检测 200 FPS¶
摘要¶
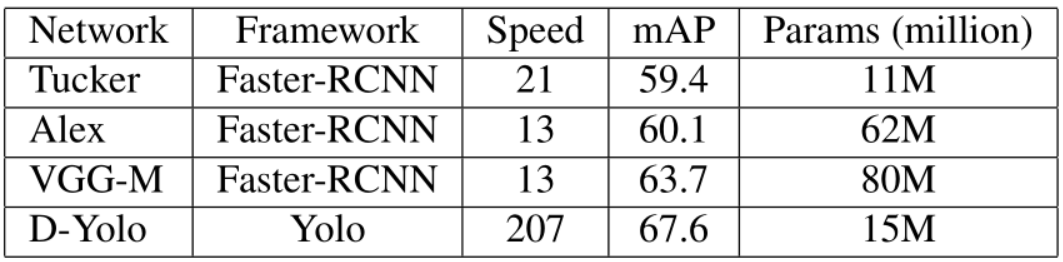
在本文中,我们提出了一种高效和快速的物体检测器,可每秒妙处理数百帧。为了实现这一目标,我们研究了对象检测框架的三个主要方面:网络架构、损失函数和训练数据(标注和未标注)。为了获得紧凑的网络架构,我们基于最近的工作引入了各种改进,以开发一种计算轻量并且达到合理性能的架构。为了进一步提高性能,在保持网络复杂性的同时,我们使用了蒸馏损失函数。蒸馏损失的引入,使我们能将更准确的教师网络的知识转移到提出的轻量级学生网络。我们为一级检测器流程提出了各种创新技术:目标尺度蒸馏损失(objectness scaled distillation loss),特征图 NMS 和用于检测的统一的单蒸馏损失函数。最后,在蒸馏损失的基础上,我们探索利用未标记数据对检测性能的提升程度。我们使用教师网络的软标签对未标记的数据进行训练。我们的最终网络比基于 VGG 的物体检测网络的参数少 10 倍,并且它达到了 200 FPS 以上的检测速度,此外我们所提出的改进将基线模型在 Pascal 数据集上的检测精度提高了 14 mAP。
F-Yolo 架构¶
作者针对大规模工业部署对速度和内存的严格要求,开发了一种低内存的高效快速(一卡多流)的物体检测器。
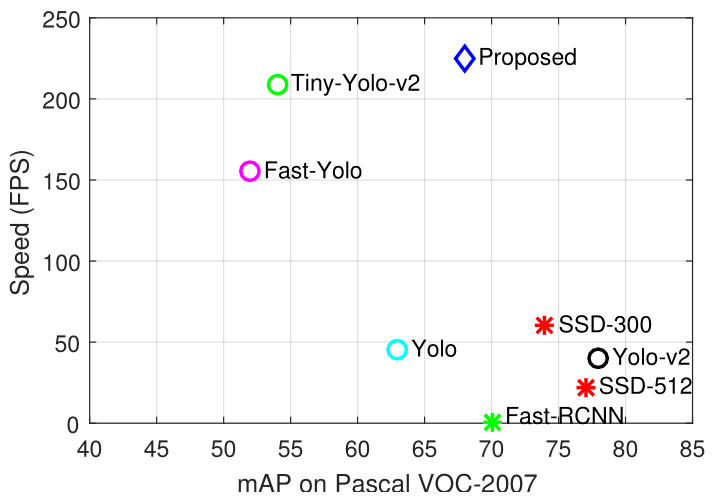
图 1 提出检测器与 SSD 和 Yolo-v2 在速度和性能上的对比
现有的快速模型如 SSD 和 YoloV2 只能达到 20-60 FPS,为了开发更快速的检测请,选择中等精度但真正高效的检测器 Tiny-Yolo[1] (Yolov2 的加速版) 作为基线模型。
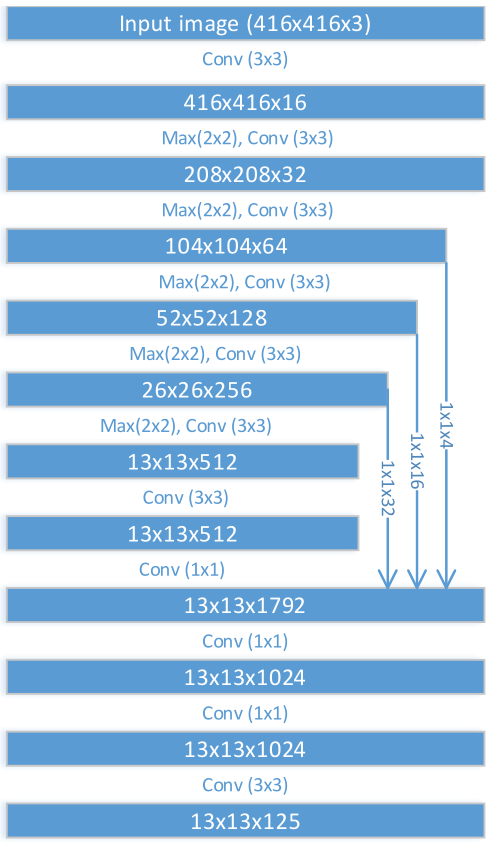
图 2 F-Yolo 基础架构
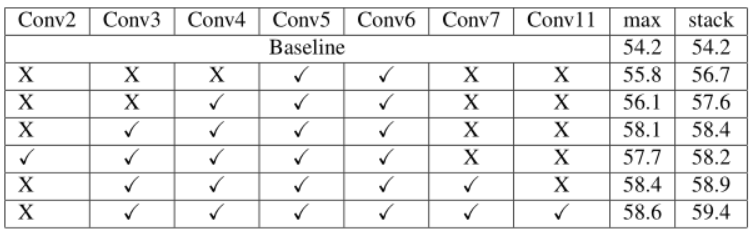
- 特征融合 (dense feature map with stacking):融合时,不同于以往使用 max-pooling 缩小分辨率,而是类似于 Yolo-v2 中的
passthrough layer, 使用 resize 将大分辨率的特征缩小,然后与小分辨率特征做 concate。如图 2 中最右边的箭头表示用conv(channels=4,kernel=1)将 \(104*104*64\) 的特征压缩到 \(104*104*4\),然后做 resize 调整布局为 \(13*13*256\)。原因是 max-pooling 容易造成空间信息丢失,使用 resize 可以将高分辨率特征图上的近邻特征堆叠到不同通道中。注意堆叠时的数据布局为(h,w,c) - 又深又窄的网络 (deep but narrow):1)更窄:在
Tiny-Yolo中,最后的几个卷积层都比较宽(通道数 1024),因为引入了特征融合也就不需要这么多卷积核了。因此将这些层的卷积核数量做削减,比如:最后一个卷积层是 125 通道,最后一个融合卷积层是 512 通道(倒数第五层,该层是基线模型的最后一层)。2)更深:这么样才能在增加网络深度的同时,又避免引入过多的计算量? 作者采用叠加 \(1*1\) 卷积的方式,因为 \(1*1\) 卷积的计算量远小于 \(3*3\) 卷积。如图 2 的最后三层。
基于这些简单的概念,改进后的轻量级框架的结果比 Tiny-Yolo 基线模型提高了 5 mAP (在 Pascal 数据集上从 54.2 mAP 提升到 59.4 mAP),并且快了 20%。将该网络命名为 F-Yolo。
网络蒸馏¶
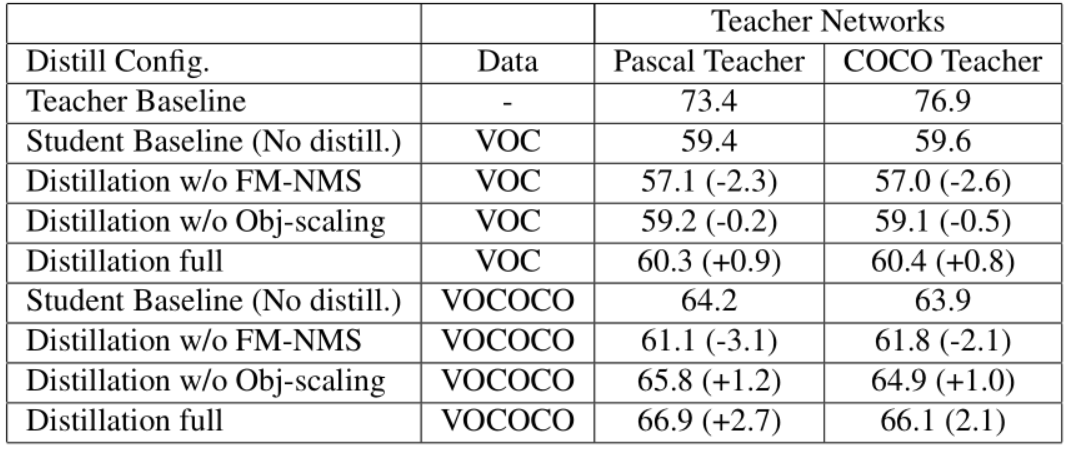
网络蒸馏 (network distillation) 是用一个复杂网络 (teacher network) 学到的知识辅助训练一个简单网络 (student network),知识以 soft label 对形式迁移。网络蒸馏是模型加速压缩领域的一个重要分支,这里引入的目的是在不增加计算量的前提下进一步提升检测性能。
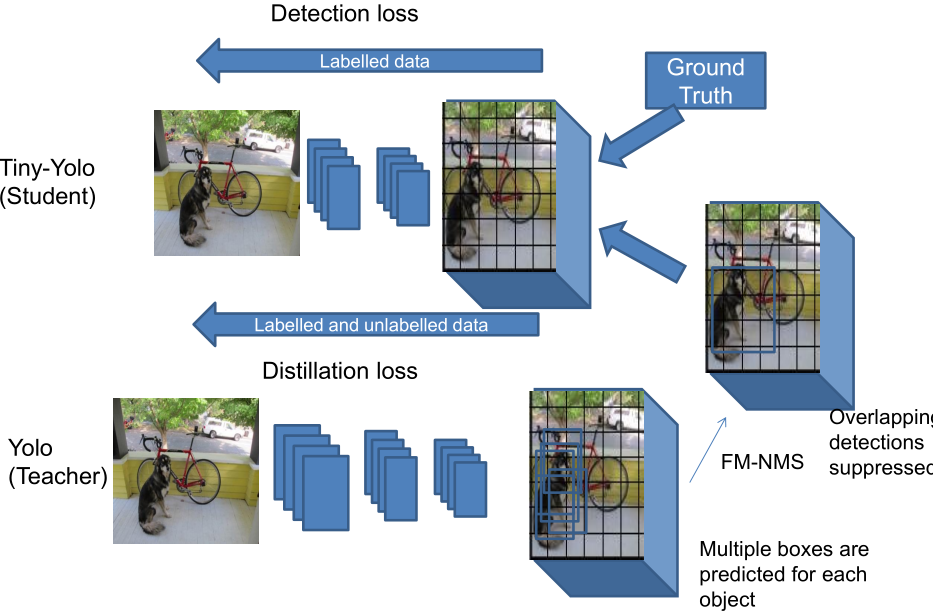
图 3 蒸馏方法的整体框架
在介绍蒸馏方法,我们先简单回顾下 Yolo-v2 的输出和损失函数。Yolo-v2 是一个单段检测器,在最后一个卷积层同时分类和回归,每个神经元预测 N 个锚框,组成最后层的 \(N \times (K+5)\) 个通道。对于每个锚框,网络会预测:边框坐标,物体概率 (objectness value) 和类别概率。所以 Yolo-v2 的整体优化目标可以分为三部分:回归损失,物性概率和分类损失,表示为:
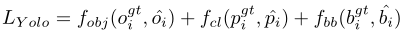

图 4 Yolo-v2 的输出格式
- Objectness scaled distillation:现有的检测器蒸馏方法采用教师网络的最后一个卷积层来迁移知识,这适用于 RCNN 系列的两段检测器。对于 Yolo-v2 这样的单段检测器,没有 RPN 的提前过滤机制,最后卷积中密集的负锚框预测会严重影响对边框回归的训练。因此作者采用基于物体概率过滤的蒸馏方法:对于物体概率较低的锚框只迁移物体概率,对于物体概率较高的锚框全部迁移。
对于有标签数据,接下来的关键是如何有效结合教师网络的蒸馏损失和标签的检测损失。
物体概率损失:
其中 \(\lambda_D\) 是蒸馏损失的平衡系数,文中默认为 1。
类别概率损失: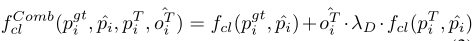
边框回归损失: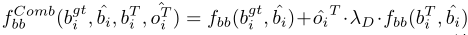
区别在于蒸馏损失部分多了个因子 \(\hat{o_i}^T\),这是教师网络的预测的物体概率,当物体概率较低时,蒸馏损失就几乎不起作用了。 - Feature Map-NMS:NMS 是物体检测的必要的后处理过程,用于出掉重复的检测框,传统的 NMS 算法和网络结构的训练时相互独立的。如果不做 NMS,直接将 教师网络的输出迁移到学生网络,会导致蒸馏损失因相邻区域的重复迁移而非常大,容易对 anchor 覆盖率大的物体过拟合。因此采用 FM-NMS 对特征图上重复的蒸馏目标进行合并。假设几个相邻的 grid cell 所预测的 bbox 的类别一样,那么这些 bbox 极有可能预测的是用一个 object。基于这种假设,FM-NMS 对每个 \(3\times 3\) 的 grid cell 中预测类别相同的 bbox 的物体概率进行排序,只对排名第一的 bbox 进行知识迁移。
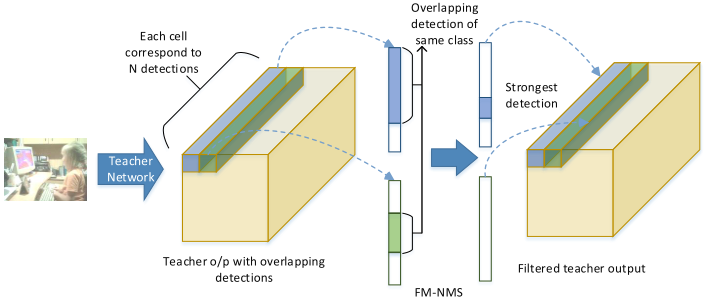
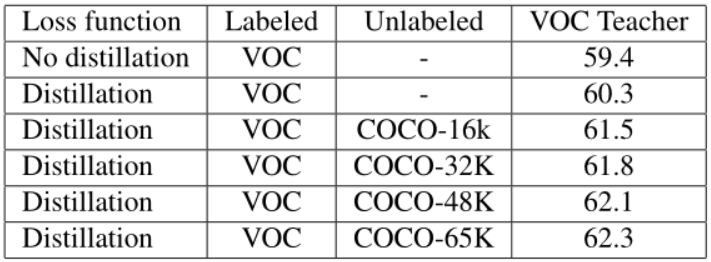
图 5 教师网络输出的相邻预测间的协同过滤(重复) - 无标签数据:突破标签数据的受限性,在使用无标签数据的时候,只使用教师网络的 soft label 来训练学生网络。具体而言,但样本标签不存在是,直接将标签的检测损失置为零,这样可以在有标签和无标签的混合数据上无缝训练学生模型。
实现细节¶
- 深度学习库: Darknet
- backbone: 使用 ImageNet 上预训练的 Tiny-Darknet 作为 baseline.
- 数据扩充:随机光学失真,随机切割,缩放到 \(2024^2\),水平镜像,保留中心在内部的人脸。且特别过滤掉长或宽小于 20px 的人脸。
- 锚框匹配:1. 对于每个标注框,匹配最大的锚框;2. 匹配大于阈值 0.5 的锚框。
- 损失函数:softmax and smooth-L1 loss
- 难负例挖掘:对于负锚框排序并取损失较大者,保证正负比例为 1:3。
- 优化:初始化 “xaiver”,batch-size=32,学习率 \(10^-3\)
- 推理:过滤简单背景锚框 0.05,输出 top-400,经过 NMS-0.3,输出最终 top-200。
实验¶
- 实验环境:Caffe,GPU: Titan X (Pascal) with cuDNN v5.1 | CPU: E5-2660v3 (2.6GHz)