快速人脸检测¶
FaceBoxes¶
摘要¶
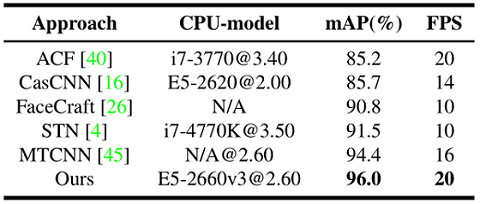
虽然在人脸检测方面已经取得了巨大进步,但如何在 CPU 的受限计算资源下实现精准的实时人脸检测,依然是一个开放性的挑战难题。为了应对这一挑战,我们提出了一种新的人脸检测器:FaceBoxes,在速度和准确性方面都表现出色。具体来说,我们的方法具有轻量级但功能强大的网络结构,包括快速消化卷积层(Rapidly Digested Convolutional Layers, RDCL)和多尺度卷积层(Multiple Scale Convolutional Layers, MSCL)。RDCL旨在使 FaceBoxes 能够在 CPU 上实现实时检测速度。MSCL 旨在丰富感受野并散布各层上的锚框,以处理各种尺度的人脸。此外,我们提出了一种新的锚点致密化策略,使不同类型的锚点在图像上具有相同的密度,从而显着提高了小脸部的召回率。因此,对于 VGA 分辨率的图片,探测器在单个 CPU 核心上能以 20 FPS 运行,在 GPU 上能以 125 FPS 运行。而且,FaceBoxes 的检查速度不随人脸个数变化。我们全面评估了这种方法,并在多个人脸检测基准数据集(包括 AFW, PASCAL face 和 FDDB)上达到了最先进的检测性能。
网络框架¶
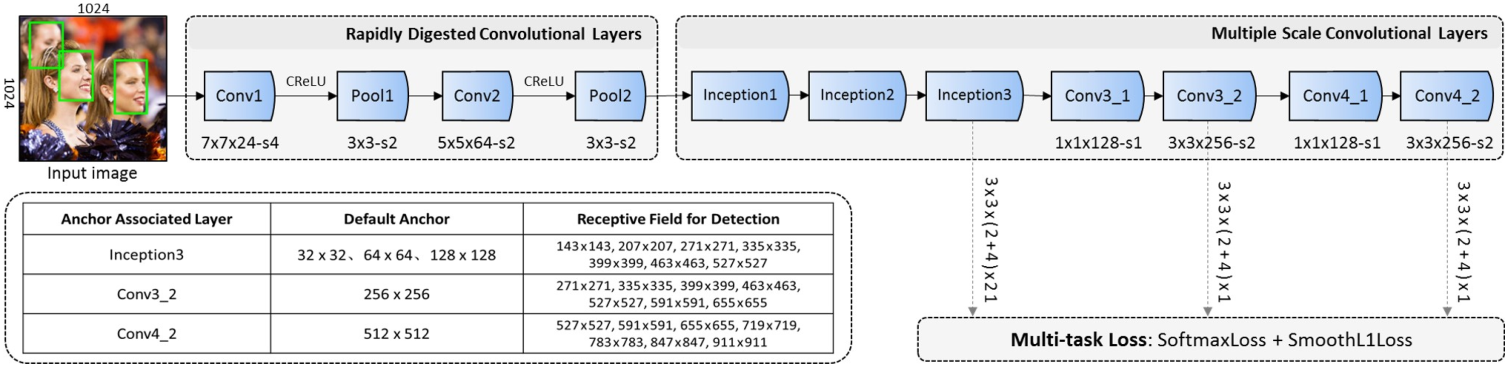
图 1 FaceBoxes 框架和锚框设置
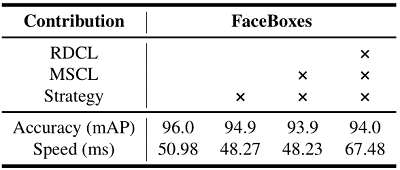
- 快速消化卷积层 RDCL:1) 快速削减输入分辨率 32 倍 (4,2,2,2);2) 选择合适的卷积核:conv(7,5), pool(3);3) 削减输出通道,使用 C.ReLU[2] 激活。C.ReLU 的动机来自于对 CNN 的可视化,即较低层的特征(正反)成对出现。因此 C.ReLU 通过在应用 ReLU 之前简单地并联正负输出使通道数加倍,从而在精度下降可忽略的情况下,显著提升速度。
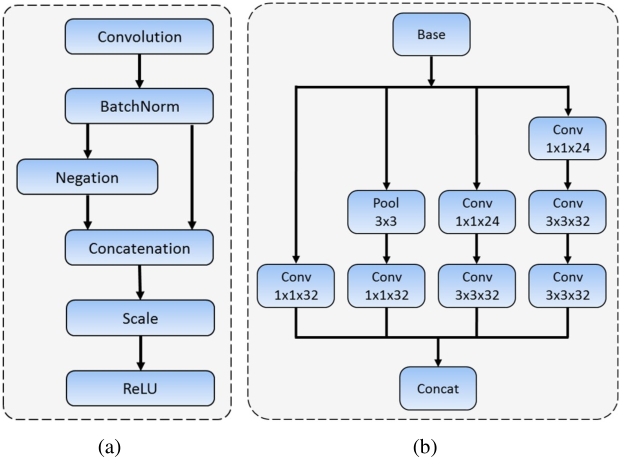
图 2 (a) C.ReLU 模块 (b) Inception 模块 - 多尺度卷积层 MSCL:1) 多尺度检测特征 2) 多感受野:Inception
- 锚框致密化:定义锚框平铺密度 \(A_{density}=A_{scale}/A_{interval}\),根据图 1 中锚框设置,相应的平铺密度是 (1,2,4,4,4),因尺存在密度不均匀问题。对于锚框太稀疏的小尺度,采用在原始锚框中心附近平铺 \(n^2\) 个锚框使其致密化。
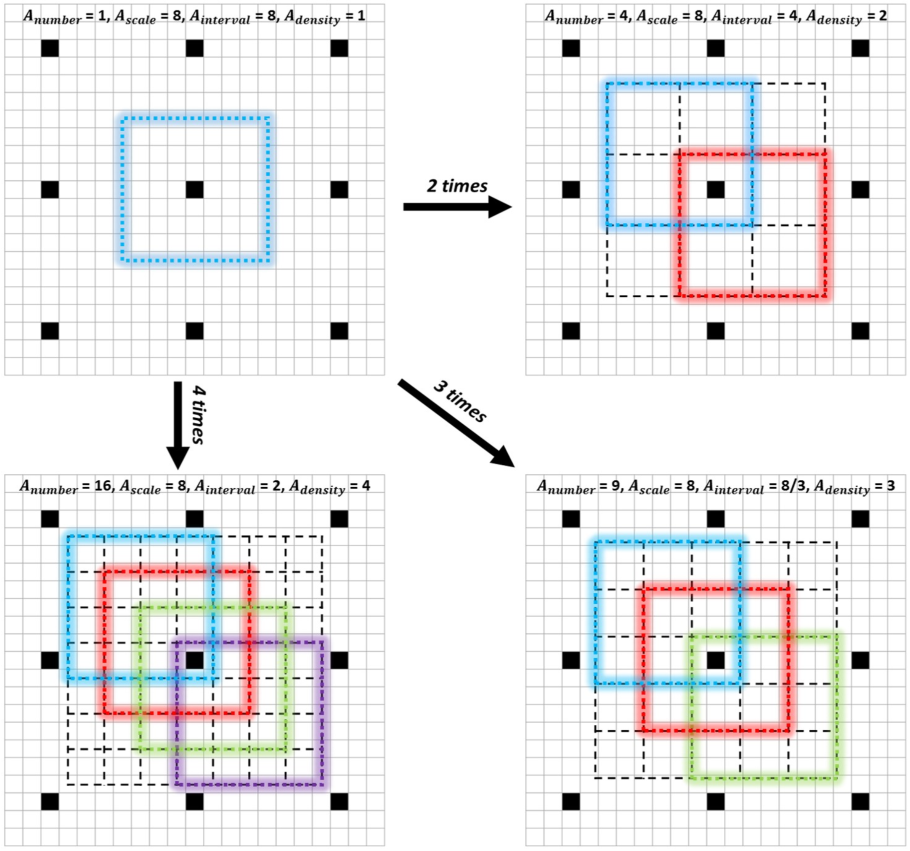
图 3 锚框致密化
训练和推理¶
- 数据扩充:随机光学失真,随机切割,缩放到 \(1024^2\),水平镜像,保留中心在内部,且长宽均大于 20 的人脸。
- 锚框匹配:1. 对于每个标注框,匹配最大的锚框;2. 匹配大于阈值 0.35 的锚框。
- 损失函数:softmax,smooth-L1 loss。
- 难负例挖掘:对于负锚框排序并取损失较大者,保证正负比例为 1:3。
- 其他细节:初始化 xaiver,优化 SGD-M,batch-size=32,初始学习率 \(10^-3\),实现平台 Caffe。
- 推理:对于 VGA 分辨率图片有 8525 个方框。首先使用 0.05 过滤多数负样本,然后使用 NMS-0.3,输出 top-200。
DCFPN¶
摘要¶
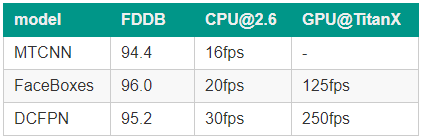
对于人脸检测来说,追求准确和追求效率是互相冲突的,因此追求准确的模型往往在检测效率上做出让步。为了解决这种冲突,我们的核心思想是缩小输入图像并专注于检测小脸。具体来说,我们提出了一种新的人脸检测器:DCFPN (Densely Connected Face Proposal Network),在 CPU 上具有高精度和实时性。一方面,我们巧妙地设计了一个轻量但强大的全卷积网络,兼顾了准确和效率;另一方面,我们使用密集锚框策略并提出了 fair L1 loss 来很好地处理小脸。因此,对于 VGA 分辨率的图片,我们的方法可以在单个 2.6 GHz CPU 核心上达到 30 FPS,在 GPU 上达到 250 FPS。我们在 AFW,PASCAL face 和 FDDB 数据集上实现了最先进的性能。
网络框架¶
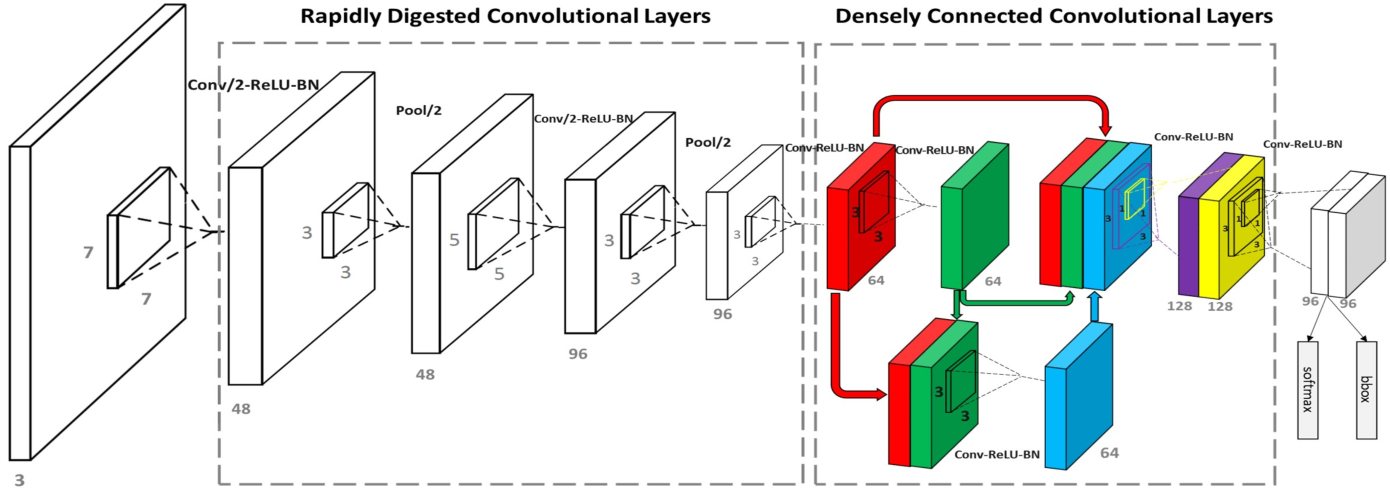
图 1 DCFPN 框架
- 轻量但有效的框架:
- 快速消化卷积层 RDCL:通过快速的又窄(通道:二分类不需要那么多特征)又大(感受野:减缓空间信息损失)的卷积核,将分辨率快速缩减到 1/16。
- 密集连接卷积层 DCCL:使用两个 Inception 结构融合三层卷积特征,起到丰富感受野尺度和有效组织特征的不同抽象层次。
- 在最后一个卷积层上关联五个尺寸的默认锚框,以实现多尺度检测。
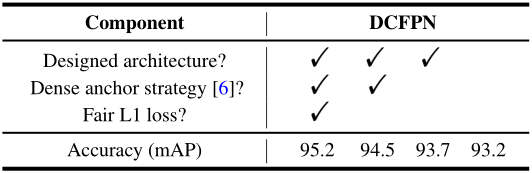
表 1 最后层包含的感受野和默认锚框尺寸 
- 密集锚框策略:默认的五个锚框尺寸都关联在最后的卷积层上,共享相同的锚框间隔,16px。小尺寸锚框的平铺太稀疏,会导致小脸检测的召回率太低。因此将尺寸为 16 的锚框密集到间隔为 4px,尺寸为 32 的锚框密集到间隔为 8px,最终对每个中心,构成 23 个默认锚框:1616 + 432 + 164 + 1128 + 1256。

图 2 (1) 居中的 5 个不同尺度的锚框,(b) \(16^2\) 密集化,(c) \(32^2\) 密集化 - Fair L1 Loss:检测函数使用 Softmax 分类损失和 Fair L1 回归损失,直接回归预测框的相对中心和长宽:
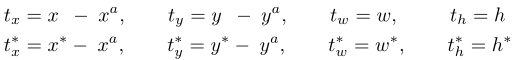 使用尺度归一化:
使用尺度归一化: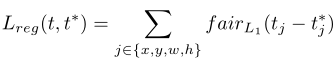
其中: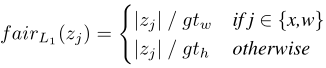
其实这只不过是普通使用方法下的 L1 loss,谈不上创新。
训练和推理¶
- 数据扩充:随机光学失真,随机切割,缩放到 \(512^2\),水平镜像,保留中心在内部的人脸。
- 锚框匹配:1. 对于每个标注框,匹配最大的锚框;2. 匹配大于阈值 0.5 的锚框。
- 难负例挖掘:对于负锚框排序并取损失较大者,保证 50%。
- 其他细节:高斯初始化,优化 SGD-M,batch-size=48,初始学习率 0.1,实现平台 Caffe。